
We build Microservices
So, what’s the big deal with microservices? Well, there are numerous benefits to building these little guys compared to the traditional monolithic architecture of days long gone:
- Small codebase
- Reusable
- Loosly coupled
- Easy to enhance and extend
- Easy to deply and scale
- Plug-and-play format
I won’t waste your time telling you why you should be using microservices, there are plenty of folks advocating this approach already. You can refer to MartinFowler.com and these guys for more information about what microservices are and the advantages they have.
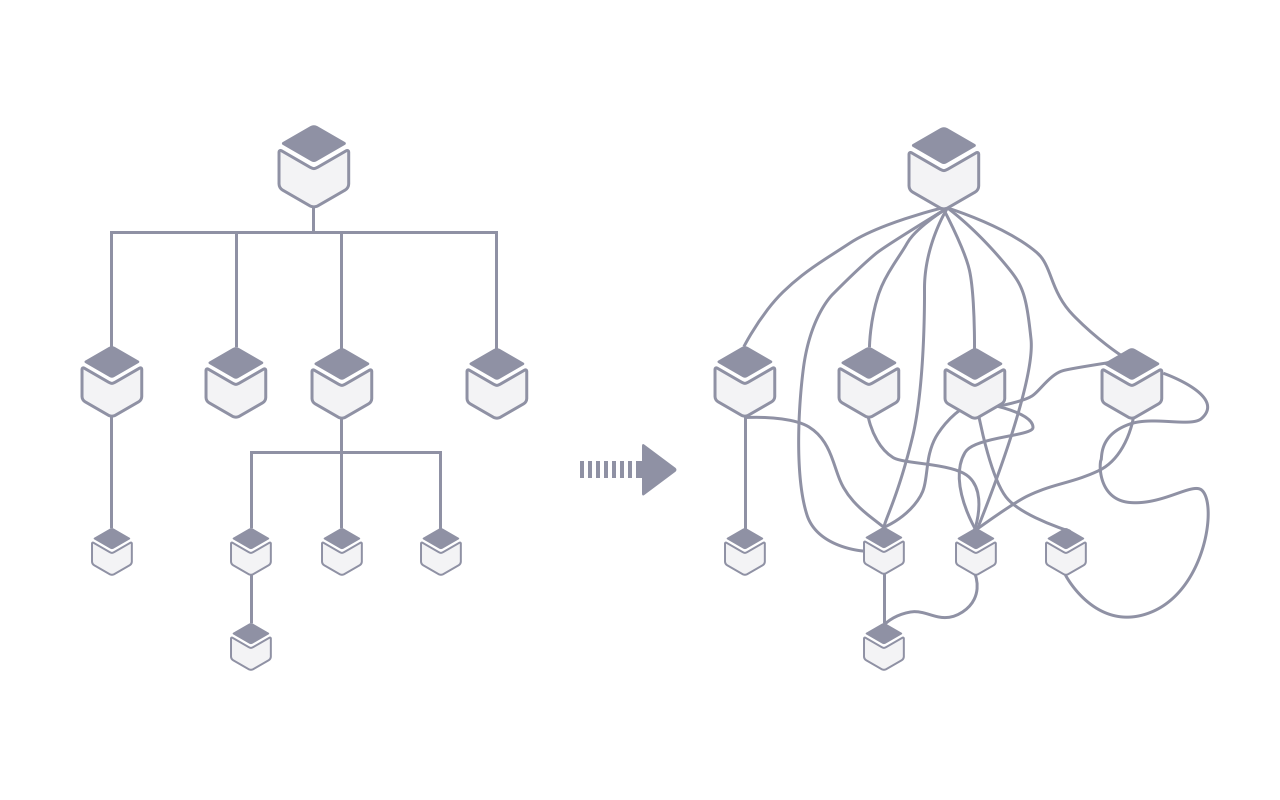
Despite their extreme usefulness, microservices are certainly not some silve bullet for all of you backend problems. One of their biggest downfalls is the complexity of interaction between the servcies you build.
We use node.js and loopback to build REST API services, which means the we mainly rely HTTP(S) protocal, As you start to build the backend, it’s not too difficult to keep a clean and graceful structure at beginning, because you can definately differentiate the upstream and downstream services clealy and neatly. However as the requirements increase in volume and complexity and the system evolves, you may find you messed something up and the API callings are now looking like your mother’s spaghetti!
Why we use message queues
The cross dependency means the system is tightly coupled, so no single service can go it alone without cooperation from other services. We use the message queue as a supplement for decoupling and keeping the the architecture flexible.
Acturally, in addition to the decoupling, we expect the following features from message queue:
- A mechanism with retry(and delay retry upon failure)
- Pub-sub(publish-subscriber) pattern
Candidates
We have 2 candidates for serving as our message queue platfom: RabbitMQ and NSQ, both have their own pros and cons, so let’s evaluate.
Pros of RabbitMQ
- Based on the open standard protocal: AMQP
- Mature and stable
- Introcude
exchangebetween producer and consumer and fledged with lots of patterns(Direct/Worker/Pub-Sub/Route/RPC…)
Cons of RabbitMQ
- A bit steep learning curve
- Not easy to implement retry with failiure.
Pros of NSQ
- Good at distributed topologies with no SPOF, which means high available(even if some nodes go down you can still use the messaging service)
- One concise message model
- Supoort retry with delay naturally
Cons of NSQ
- Messages are not durable by default
Why we choose NSQ
First, the message model of NSQ is simple and direct. No middle man no broker. All you need do is just define the producer and consumer. If you need fanout or broadcast, you can add multiple channels for the topic.
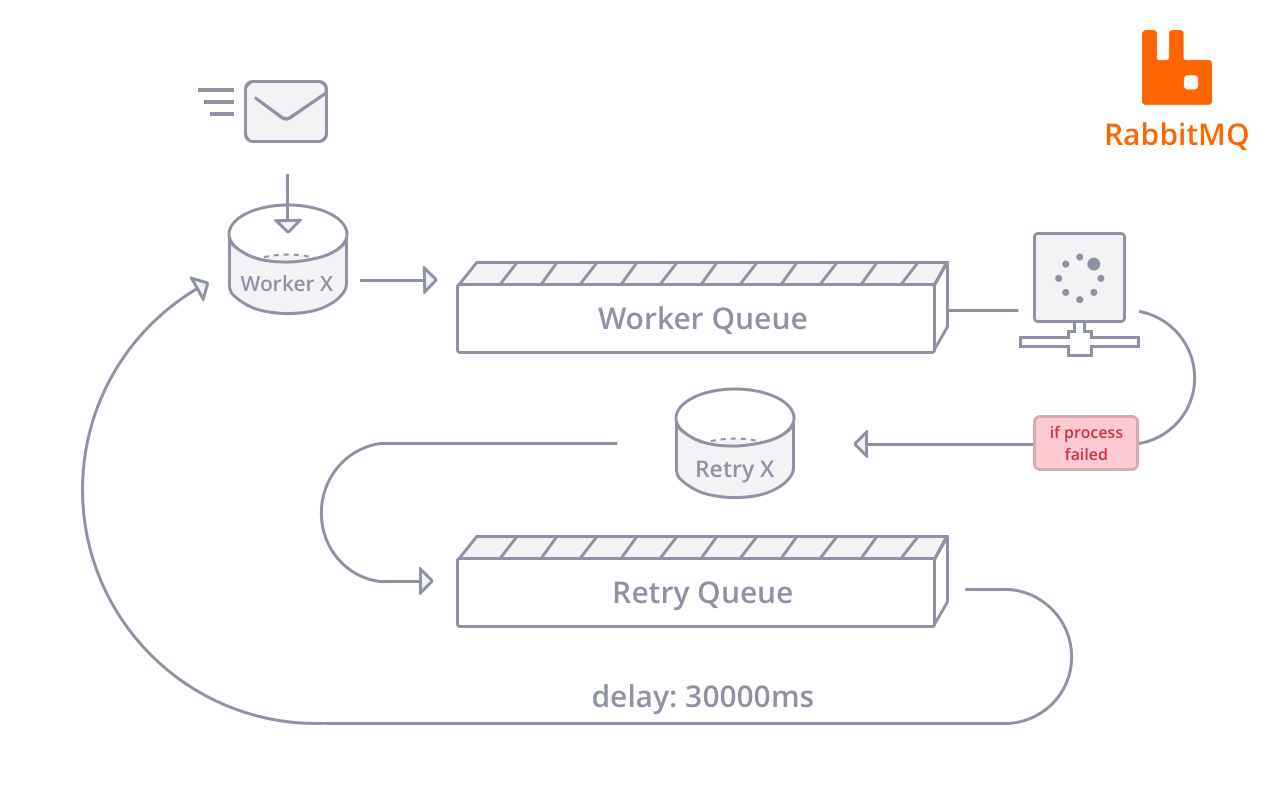
Second, we need retry with a delay mechanism. Though it is doable to use RabbitMQ, it’s not so that easy to manage. The main approach for this is using an additional deadletter exchange to simulate the delay-attempts.
Here’s the gist of how it works. It’s an unnecessary hassle, so we avoid tit whenever possible.
If you use NSQ, you merely need to call requeue() with parameter of delay, then you’re done!
The last reason we choose NSQ is its core is written by Go. Aside fromn Node.js, we also use Go for some of our backend porjects, let’s keep trying and chanlleging new techonolies. :D
Something worth mentioning again, NSQ is not perfect and does have its pain points (e.g. if you want to ensure strong message durability), so you should be aware of the following shortcomings.
- No message replication and it’s mainly in memory.
- No publisher confirmation. If there’s a failure in the nsqd node when the message happens to arrive, you lost this message.
There is roadmap of NSQ’s durability and delivery guarantee. To solve the problems above you can duplicate the message with the same topic to ensure it will be delivered at least once(but more than once in most of cases), this means you need your client to de-dupe or make the operation idempotent.
How we use NSQ
There’re plenty of client libraries in NSQ website. We use the offical JavaScript client nsqjs to build our loopback based microservice. However we are not satisfied with the Writer interface, because you have to known the nsqd address beforehand and pass it to the Writer, which is not at all practical. We may scale the nsqd cluster according the needs and the nsqd itself should be able to auto-discovered(not only for consumer but also for the producer side).
That’s why we build the library nsq-strategies, a wrapper of official client library(nsqjs) with different strategies. Currently it supports round-robin and fanout strategies. For example, you now can transfer the lookupd addresses to the producer which means you don’t need to change the code when the nsqd cluster changes and the prodcuer would pick one of nsqd nodes in a round-robin way for sending message.const Producer = require('nsq-strategies').Producer;
const p = new Producer({
lookupdHTTPAddresses: ['127.0.0.1:9011', '127.0.0.1:9012']
}, {
strategy: Producer.ROUND_ROBIN
});
p.connect((errors) => {
p.produce('topic', 'message', (err) => {
if (err) {
console.log(err);
}
});
});
Wrapping things up
If you are building microservies, you should consider adopting a message queue as a supplement and give it a try with NSQ (or RabbitMQ).
Use it then improve it, like we did. That’s the way we build apps that matters.
Finally thanks to @hopechen1028 and @jonathangoodwin for illustration and help to polish my words.